I have been working and playing with prediction models for a very long time. After generating a model, or more likely several competing models, it is a common practice to calculate various measures of accuracy and precision. In practice, this means calculating a dozen or so error metrics, such as the mean error, mean squared error, standard error, etc. I never thought about it, but then it dawned on me that I am perhaps wasting my energy on calculating too many different error metrics.
OK, some duplication is inevitable. We need a measure of accuracy and a measure of precision, but why calculate half a dozen of them? This prompted me to write this white paper that you can download here.
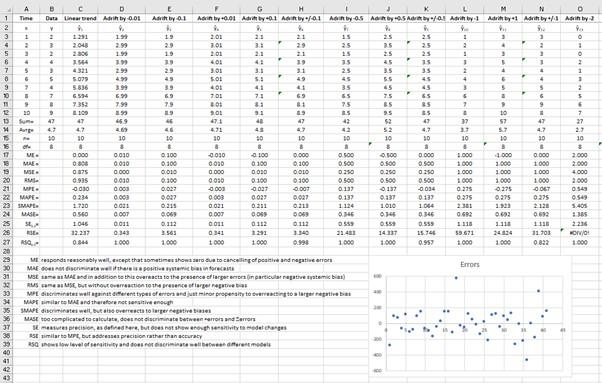
The paper uses a simple experiential approach to compare a number of competing model error metrics and recommends those that seem to convey the most valuable information. If another metric conveys similar information, it is not recommended as it does not convey any new information than the recommended one.
If you are a "fan" of the r-squared error, I apologize in advance, but you might get upset with this paper.
Hope you find it useful.